Spring WebFlux 源码分析与适用场景
关于WebFlux
Spring Framework 5提供了完整的端到端响应式编程的支持。这是一种不同于Servlet的全新的编程范式和技术栈,它基于异步非阻塞的特性,能够借助EventLoop以少量线程应对高并发的访问,提高服务的吞吐量。

对Spring 5的Spring Boot 2.0来说,新加入的响应式技术栈是其主打核心特性。具体来说,Spring Boot 2支持的响应式技术栈包括如下:
- Spring Framework 5提供的非阻塞web框架Spring Webflux。
- 遵循响应式流规范的兄弟项目Reactor,可参考https://chinalhr.github.io/post/reactive-programming-reactor/。
- 支持异步I/O的Netty、Undertow等框架,以及基于Servlet 3.1+的容器(如Tomcat 8.0.23+和Jetty 9.0.4+)。
- 支持响应式的数据访问Spring Data Reactive Repositories。
- 支持响应式的安全访问控制Spring Security Reactive。
WebFlux对比SpringMVC并发模型
SpringMVC基于的Servlet并发模型
servlet由servlet container进行生命周期管理。container启动时构造servlet对象并调用servlet init()进行初始化;container关闭时调用servlet destory()销毁servlet;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。
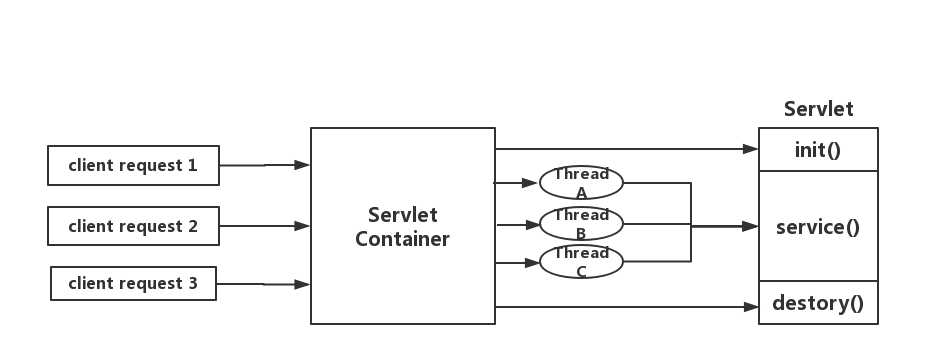
处理请求的时候同步操作,一个请求对应一个线程来处理,并发上升,线程数量就会上涨(上线文切换,内存消耗大)影响请求的处理时间。现代系统多数都是IO密集的,同步处理让线程大部分时间都浪费在了IO等待上面。虽然Servlet3.0后提供了异步请求处理与非阻塞IO支持,但是使用它会远离Servlet API的其余部分,比如其规范是同步的(Filter, Servlet)或阻塞的(getParameter, getPart),而且其对Response的写入仍然是阻塞的。
WebFlux并发模型
WebFlux模型主要依赖响应式编程库Reactor,Reactor 有两种模型 Flux 和 Mono,提供了非阻塞、支持回压机制的异步流处理能力。WebFlux API接收普通Publisher作为输入,在内部使其适配Reactor类型,使用它并返回Flux或Mono作为输出。
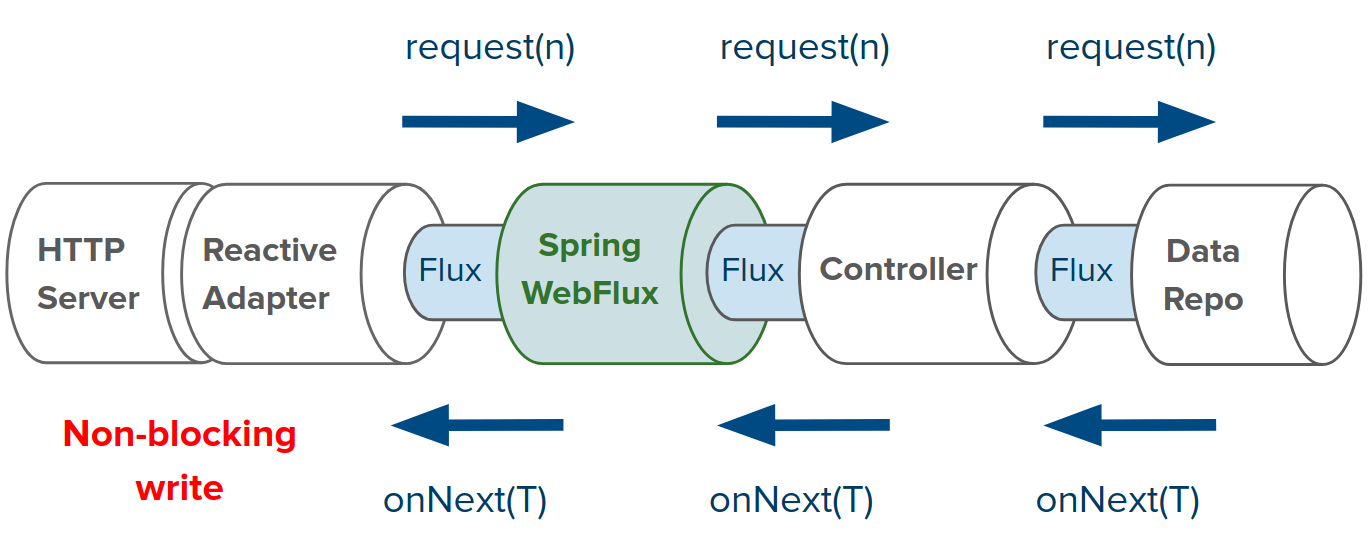
WebFlux 使用Netty作为默认的web服务器,其依赖于非阻塞IO,并且每次写入都不需要额外的线程进行支持。
也可以使用Tomcat、Jetty容器,不同与SpringMVC依赖于Servlet阻塞IO,并允许应用程序在需要时直接使用Servlet API,WebFlux依赖于Servlet 3.1非阻塞IO。使用Undertow作为服务器时,WebFlux直接使用Undertow API而不使用Servlet API。
当WebFlux运行在Netty服务器上,其线程模型如下:
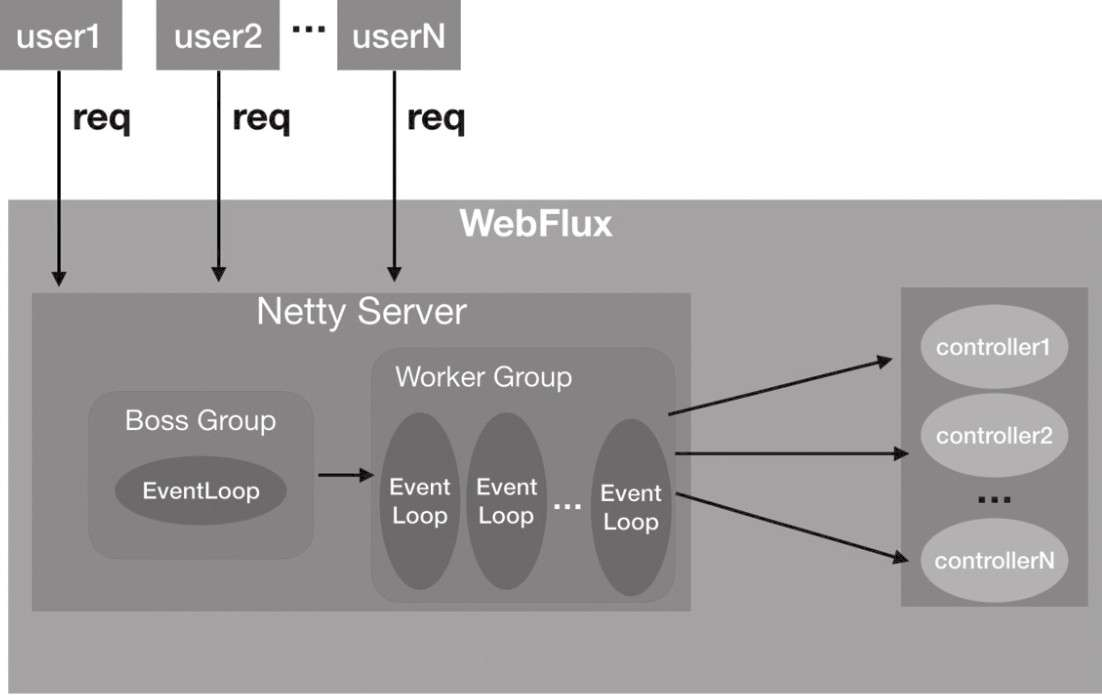
NettyServer的Boss Group线程池内的事件循环会接收这个请求,然后把完成TCP三次握手的连接channel交给Worker Group中的某一个事件循环线程来进行处理(该事件处理线程会调用对应的controller进行处理)。所以WebFlux的handler执行是使用Netty的IO线程进行执行的,所以需要注意如果handler的执行比较耗时,会把IO线程耗尽导致不能再处理其他请求,可以通过Reactor的publishOn操作符切换到其他线程池中执行。
使用说明
参考:https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html#webflux
性能
响应式和非阻塞并不是总能让应用跑的更快,况且将代码构建为非阻塞的执行方式本身还会带来少量的成本。但是在类似于WEB应用这样的高并发、少计算且I/O密集的应用中,响应式和非阻塞往往能够发挥出价值。
对比SpringMVC使用的Servlet模型,增加Servlet容器处理请求的线程数量可以缓解这一问题,但是增加线程是有成本的,JVM中默认情况下在创建新线程时会分配大小为1M的线程栈,所以更多的线程意味着需要更多的内存;更多的线程会带来更多的线程上下文切换成本。
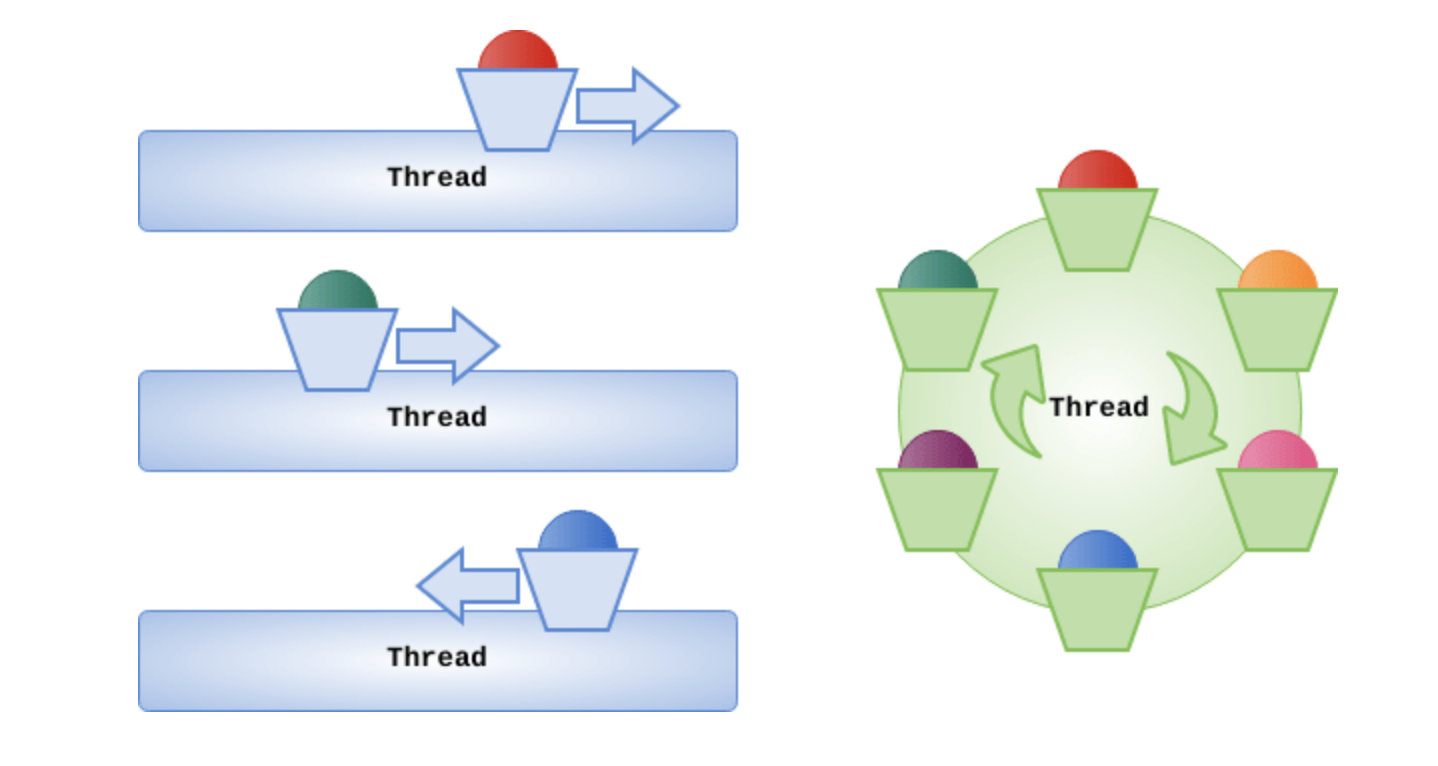
webflux对比SpringMVC的性能测试
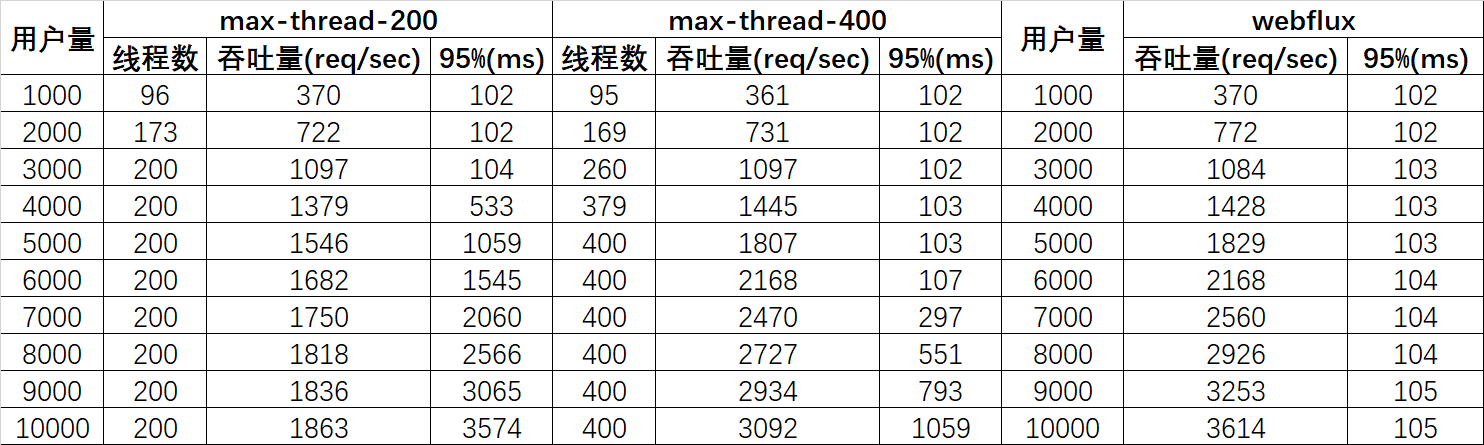
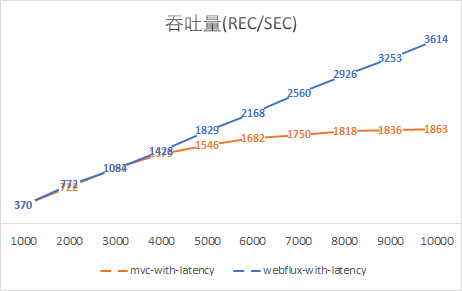
对于运行在异步IO的之上的WebFlux应用来说,其工作线程数量始终维持在一个固定的数量上,通常这个固定的数量等于CPU核数。从测试图中可以看到,随着用户数的增多,webflux吞吐量基本呈线性增多的趋势,95%的响应都在100ms+的可控范围内返回了,并未出现延时的情况。而SpringMVC线程数达到200/400前,95%的请求响应时长是正常的,之后呈直线上升的态势;
结论:非阻塞的处理方式规避了线程排队等待的情况,从而可以用少量而固定的线程处理应对大量请求的处理,提升应用的吞吐量和伸缩性。
WebFlux请求分发
reactor的map,flatMap,concatMap
- map
map通过对每个元素应用转换函数来同步转换由此发出的元素。
public final <V> Flux<V> map(Function<? super T,? extends V> mapper)
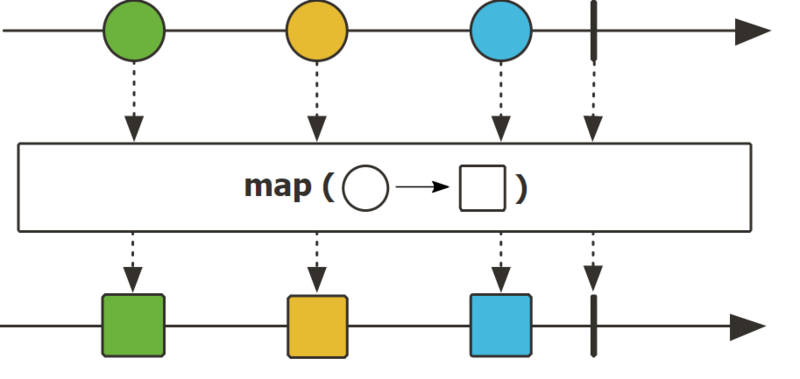
//同步执行乘法操作
Flux.just(1,2,3,4,5)
.log()
.map(i->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
return i*10;
})
.subscribe(c->log.info("getInt:{}",c));
- flatMap
flatMap通过对发出的元素异步转换为 Publisher,然后通过合并将这些内部发布者扁平化为单个Flux,从而允许它们交错。
public final <R> Flux<R> flatMap(Function<? super T,? extends Publisher<? extends R>> mapper)
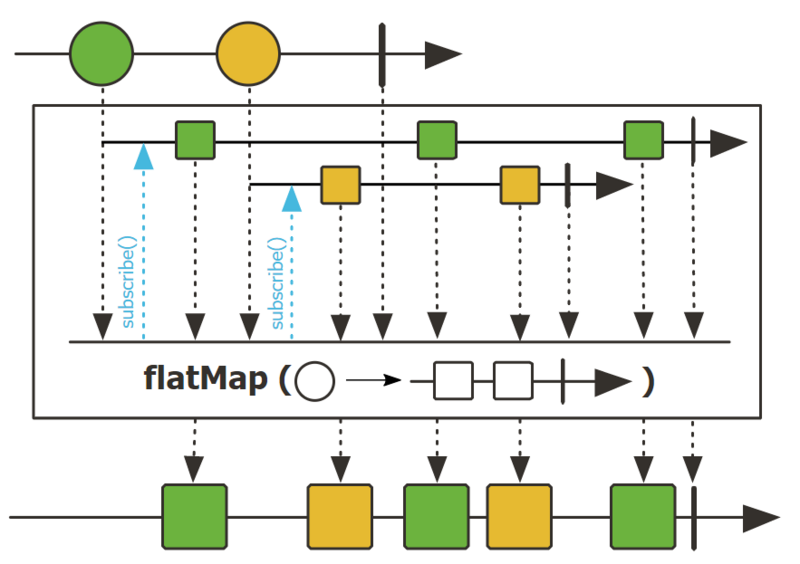
//异步执行乘法
Flux.just(1,2,3,4,5)
.log()
.flatMap(i-> Flux.just(i*10).delayElements(Duration.ofSeconds(1)))
.subscribe(c ->log.info("getInt:{}",c));
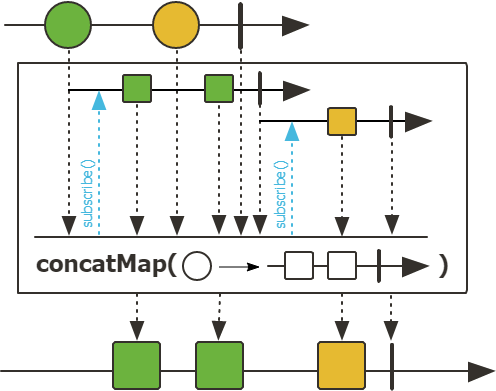
- concatMap
concatMap 通过对发出的元素异步转换为 Publisher,然后通过合并将这些内部发布者扁平化为单个Flux,与 flatMap不同的是,concatMap会根据原始流中的元素顺序依次把转换之后的流进行合并。
public final <V> Flux<V> concatMap(Function<? super T,? extends Publisher<? extends V>> mapper)
WebFlux 的DispatcherHandler
Spring MVC 的前端控制器是 DispatcherServlet,而WebFlux 的前端控制器是 DispatcherHandler,它实现了 WebHandler接口。DispatcherHandler完成 handler 的查找、调用和结果处理等步骤,关联的Bean如下:
| Bean 类型 | 解释 |
|---|---|
| HandlerMapping | 将请求映射到对应的 handler。主要的 HandlerMapping 实现有处理 @RequestMapping 注解的 RequestMappingHandlerMapping ,处理函数路由的RouterFunctionMapping,以及处理简单 URL 映射的 SimpleUrlHandlerMapping。 |
| HandlerAdapter | 帮助 DispatcherHandler 调用请求对应的 handler,而不用关心该 handler 具体的调用方式。例如,调用一个通过注解的方式定义的 controller 就需要寻找对应的注解,而 HandlerAdapter 的主要目的就是为了帮助 DispatcherHandler 屏蔽类似的细节. |
| HandlerResultHandler | 处理 handler 调用后的结果,并生成最后的响应。参考 Result Handling。 |
public interface WebHandler {
/**
* Handle the web server exchange.
* @param exchange the current server exchange
* @return {@code Mono<Void>} to indicate when request handling is complete
*/
Mono<Void> handle(ServerWebExchange exchange);
}
public class DispatcherHandler implements WebHandler, ApplicationContextAware {
...
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
//流程1
if (this.handlerMappings == null) {
return createNotFoundError();
}
return Flux.fromIterable(this.handlerMappings)
//流程2
.concatMap(mapping -> mapping.getHandler(exchange))
.next()
//流程3
.switchIfEmpty(createNotFoundError())
//流程4
.flatMap(handler -> invokeHandler(exchange, handler))
//流程5
.flatMap(result -> handleResult(exchange, result));
}
}
ServerWebExchange对象提供 HTTP 请求-响应交互信息(包括请求参数,路径,Cookie等)
从DispatcherHandler的handle实现可以看出WebFlux的请求分发流程:
- 判断整个接口映射 mappings集合是否为空,空则创建一个 Not Found 的请求错误响应;
- 根据具体的请求地址获取对应的 handlerMapping(处理方法);
- handlerMapping为空的话找不到对应的处理方法,创建一个 Not Found 的请求错误响应;
- 通过 invokeHandler 方法找到对应的 HandlerAdapter 来完成调用
- 由 HandlerResultHandler 对结果进行处理,并生成响应
WebFlux delay方法
对于运行在异步IO的之上的WebFlux应用来说,其工作线程数量始终维持在一个固定的数量上,程序逻辑中有阻塞(如io阻塞等)需要进行异步化。如新出的WebClient工具就是将http请求io异步化,用delay方法代替sleep方法将延时异步化。
delay原理实现
public static Mono<Long> delay(Duration duration) {
return delay(duration, Schedulers.parallel());
}
public static Mono<Long> delay(Duration duration, Scheduler timer) {
return onAssembly(new MonoDelay(duration.toMillis(), TimeUnit.MILLISECONDS, timer));
}
查看delay方法源码,可以看到它里面其实构造一个MonoDelay类,并通过传入全局公用的调度器Schedulers.parallel()来调度里面的异步任务。
查看MonoDelay类的subscribe方法
public void subscribe(CoreSubscriber<? super Long> actual) {
MonoDelayRunnable r = new MonoDelayRunnable(actual);
actual.onSubscribe(r);
try {
r.setCancel(timedScheduler.schedule(r, delay, unit));
}
catch (RejectedExecutionException ree) {
if(r.cancel != OperatorDisposables.DISPOSED) {
actual.onError(Operators.onRejectedExecution(ree, r, null, null,
actual.currentContext()));
}
}
}
代码timedScheduler.schedule(r, delay, unit)方法,通过timedScheduler来调度延时任务。
查看timedScheduler的schedule方法
@Override
public Disposable schedule(Runnable task, long delay, TimeUnit unit) {
return Schedulers.directSchedule(pick(), task, null, delay, unit);
}
static Disposable directSchedule(ScheduledExecutorService exec,
Runnable task,
@Nullable Disposable parent,
long delay,
TimeUnit unit) {
task = onSchedule(task);
SchedulerTask sr = new SchedulerTask(task, parent);
Future<?> f;
if (delay <= 0L) {
f = exec.submit((Callable<?>) sr);
}
else {
f = exec.schedule((Callable<?>) sr, delay, unit);
}
sr.setFuture(f);
return sr;
}
通过directSchedule可以看出,delay方法之所以没有阻塞主线程,因为它的延时处理的逻辑包装成SchedulerTask,交给了ScheduledExecutorService执行器处理,调用delay方法的主线程就直接返回了,当delay>0是使用ScheduledExecutorService进行延迟调度。
结论
WebFlux将部分阻塞的逻辑修改为类似于delay方法的实现,利用调度执行器去异步执行阻塞的逻辑,不阻塞EventLoop线程,使得少量的工作线程可以承载更多的请求。
适用场景
使用 Spring WebFlux,下游使用的安全认证层、数据访问层框架都必须使用 Reactive API 保证上下游都是匹配的,非阻塞的。然而Spring Data Reactive Repositories 目前只支持 MongoDB、Redis 和Couchbase 等几种不支持事务管理的 NOSQL,技术选型时需要权衡利弊和风险。
- Spring MVC能满足场景的,就不需要更改为 Spring WebFlux,毕竟Reactive写法对比原本同步执行的程序写法很不同,而且很多基于Servlet线程模型的库将无法使用,如Spring Transaction……。
- 需要底层容器的支持(Netty和Servlet3.1+)。
- 适合应用在 IO 密集型的服务中(IO 密集型包括:磁盘IO密集型, 网络IO密集型),微服务网关就属于网络 IO 密集型,使用异步非阻塞式编程模型,能够显著地提升网关对下游服务转发的吞吐量。