响应式编程学习
响应式流规范
相关链接: https://github.com/reactive-streams/reactive-streams-jvm
Reactive Streams是JVM的面向流的库的标准和规范,目的是实现
- 具有处理无限数量的元素的能力
- 按序处理
- 异步地传递元素
- 必须实现非阻塞的回压(backpressure)
响应式流接口
- Publisher(发布者,发出元素)
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
- Subscriber(订阅者,接收元素并做出响应的)
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
- Subscription
public interface Subscription {
public void request(long n);
public void cancel();
}
- Processor(集合Publisher和Subscriber)
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
当执行subscribe方法时,发布者会回调订阅者的onSubscribe方法,订阅者借助传入的Subscription的request方法向发布者请求n个数据。发布者通过不断调用订阅者的onNext方法向订阅者发出最多n个数据。如果数据全部发完,则会调用onComplete告知订阅者流已经发完;如果有错误发生,则通过onError发出错误数据,同样也会终止流。
Reactor
Reactor是完全基于Reactive Streams设计和实现的库,也是 Spring 5 中反应式编程的基础。
Flux与Mono
Flux与Mono都是发布者(Publisher),一个Flux对象代表一个包含 0-N 个元素的异步序列,而一个Mono对象代表一个异步的 0-1 个元素。
- 创建数据流
Flux.fromArray(array);
Flux.fromIterable(list);
Flux.fromStream(stream);
Flux.just(...);
- 订阅
// 订阅并触发数据流
subscribe();
// 订阅并指定对正常数据元素如何处理
subscribe(Consumer<? super T> consumer);
// 订阅并定义对正常数据元素和错误信号的处理
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
// 订阅并定义对正常数据元素、错误信号和完成信号的处理
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
// 订阅并定义对正常数据元素、错误信号和完成信号的处理,以及订阅发生时的处理逻辑
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
//example
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");});
- 自定义数据流-generate
generate是一种同步地,逐个地发出数据的方法。因为它提供的sink是一个SynchronousSink, 而且其next()方法在每次回调的时候最多只能被调用一次。
public static <T> Flux<T> generate(Consumer<SynchronousSink<T>> generator);
public static <T, S> Flux<T> generate(Callable<S> stateSupplier, BiFunction<S, SynchronousSink<T>, S> generator);
public static <T, S> Flux<T> generate(Callable<S> stateSupplier, BiFunction<S, SynchronousSink<T>, S> generator, Consumer<? super S> stateConsumer);
//example
//1. 初始化状态值(state)为0
//2. 基于状态值 state 来生成下一个值(state 乘以 3)
//3. 当状态值 state = 10 ,终止序列
//4. 返回一个新的状态值 state,用于下一次调用
//element "3 x 0 = 0" , "3 x 1 = 3" , "3 x 2 = 6" ... "3 x 10 = 30"
Flux<String> flux = Flux.generate(
() -> 0,
(state, sink) -> {
sink.next("3 x " + state + " = " + 3*state);
if (state == 10) sink.complete();
return state + 1;
});
- 自定义数据流-create
更高级的创建Flux的方法,其生成数据流的方式既可以是同步的,也可以是异步的,并且还可以每次发出多个元素(create 常用的场景就是将现有的 API 转为响应式,比如监听器的异步方法)。
MyEventSource eventSource = new MyEventSource();
Flux.create(sink -> {
//向事件源注册用匿名内部类创建的监听器
eventSource.register(new MyEventListener() {
@Override
public void onNewEvent(MyEventSource.MyEvent event) {
//监听器在收到事件回调的时候通过sink将事件再发出
sink.next(event);
}
@Override
public void onEventStopped() {
//监听器在收到事件源停止的回调的时候通过sink发出完成信号
sink.complete();
}
});
}
).subscribe(System.out::println);
调试
- 单元测试工具StepVerifier
expectNext用于测试下一个期望的数据元素,expectErrorMessage用于校验下一个元素是否为错误信号,expectComplete用于测试下一个元素是否为完成信号。
StepVerifier.create(...)
.expectNext(1, 2, 3, 4, 5, 6)
.expectComplete()
.verify();
Operator(操作符)
- map: 元素映射为新元素
- flatMap: 元素映射为流
- filter: 过滤
- zip: 一对一合并:对两个Flux/Mono流每次各取一个元素,合并为一个二元组(Tuple2)
public static <T1,T2> Flux<Tuple2<T1,T2>> zip(Publisher<? extends T1> source1,Publisher<? extends T2> source2);
public static <T1, T2> Mono<Tuple2<T1, T2>> zip(Mono<? extends T1> p1, Mono<? extends T2> p2);
- transform: 可以将一段操作链打包为一个函数,这个函数能在操作期(assembly time)将被封装的操作链中的操作符还原并接入到调用 transform 的位置。
//将filter和map操作符进行了打包
Function<Flux<String>, Flux<String>> filterAndMap =
f -> f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
//将包装的函数拼装到操作链
.transform(filterAndMap)
.subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d));
// result:
// blue
// Subscriber to Transformed MapAndFilter: BLUE
// green
// Subscriber to Transformed MapAndFilter: GREEN
// orange
// purple
// Subscriber to Transformed MapAndFilter: PURPLE
- compose: 与 transform类似,将几个操作符封装到一个函数式中。区别是,这个函数式是针对每一个订阅者起作用的。对每一个subscription可以生成不同的操作链(通过维护状态值)。
AtomicInteger ai = new AtomicInteger();
Function<Flux<String>, Flux<String>> filterAndMap = f -> {
if (ai.incrementAndGet() == 1) {
return f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
}
return f.filter(color -> !color.equals("purple"))
.map(String::toUpperCase);
};
Flux<String> composedFlux =
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.compose(filterAndMap);
composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d));
composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d));
// result:
// blue
// Subscriber 1 to Composed MapAndFilter :BLUE
// green
// Subscriber 1 to Composed MapAndFilter :GREEN
// orange
// purple
// Subscriber 1 to Composed MapAndFilter :PURPLE
// blue
// Subscriber 2 to Composed MapAndFilter: BLUE
// green
// Subscriber 2 to Composed MapAndFilter: GREEN
// orange
// Subscriber 2 to Composed MapAndFilter: ORANGE
// purple
调度器&线程模型
Schedulers工具类
- 当前线程(Schedulers.immediate())。
- 可重用的单线程(Schedulers.single()),这个方法对所有调用者都提供同一个线程来使用,直到该调度器被废弃。Schedulers.newSingle()使用独占的线程。
- 弹性线程池(Schedulers.elastic())。它根据需要创建一个线程池,重用空闲线程。线程池如果空闲时间过长 (默认为 60s)就会被废弃。对于 I/O 阻塞的场景比较适用。Schedulers.elastic()能够方便地给一个阻塞 的任务分配它自己的线程,从而不会妨碍其他任务和资源。
- 固定大小线程池(Schedulers.parallel()),所创建线程池的大小与CPU个数等同,适合做并行计算。
- 自定义线程池(Schedulers.fromExecutorService(ExecutorService))基于自定义的ExecutorService创建 Scheduler。
// 基于Callable的Mono
Mono.fromCallable(() -> getStringSync())
// 使用subscribeOn将任务调度到Schedulers内置的弹性线程池执行
.subscribeOn(Schedulers.elastic())
.subscribe(System.out::println);
publishOn与subscribeOn区别
Reactor 提供了两种在响应式链中调整调度器 Scheduler 的方法:publishOn 和 subscribeOn。 它们都接受一个 Scheduler 作为参数,从而可以改变调度器。
- publishOn: publishOn 的用法和处于订阅链(subscriber chain)中的其他操作符一样。它将上游 信号传给下游,同时执行指定的调度器 Scheduler 的某个工作线程上的回调。 它会改变后续的操作符的执行所在线程 (直到下一个 publishOn 出现在这个链上)。
- subscribeOn: 用于订阅(subscription)过程,作用于那个向上的订阅链(发布者在被订阅 时才激活,订阅的传递方向是向上游的)。所以,无论把 subscribeOn 至于操作链的什么位置, 它都会影响到源头的线程执行环境(context),不会影响到后续的 publishOn,后者仍能够切换其后操作符的线程执行环境。
数据流配置Context
类似于 ThreadLocal ,区别是Context作用于一个 Flux 或一个 Mono 上,而不是应用于一个线程(Thread),其生命周期伴随整个数据流。
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
错误处理&重试
错误处理
- 捕获并返回一个静态的缺省值:onErrorReturn方法能够在收到错误信号的时候提供一个缺省值。
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");
- 捕获并执行一个异常处理方法或计算一个候补值来顶替:onErrorResume方法能够在收到错误信号的时候提供一个新的数据流。
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k))
.onErrorResume(e -> getFromCache(k));
- 捕获并再包装为某一个业务相关的异常,然后再抛出业务异常:onErrorMap。
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));
- 捕获并执行操作如记录错误日志等,然后继续传递:doOnError(只读,不会对数据流造成影响)。
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k))
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k);
})
.onErrorResume(e -> getFromCache(k));
- 使用 finally 来清理资源:doFinally方法在序列终止(onComplete、onError)时被执行,并且支持判断终止事件。
LongAdder statsCancel = new LongAdder();
Flux<String> flux =
Flux.just("foo", "bar")
.doFinally(type -> {
if (type == SignalType.CANCEL)
statsCancel.increment();
})
.take(1);
重试
retry可以对出现错误的序列进行重试,retry对于上游Flux是采取的重订阅(re-subscribing)的方式,出错了retry会从新订阅了原始的数据流执行n次。
Backpressure回压
前提
- 发布者与订阅者不在同一个线程中,因为在同一个线程中的话,通常使用传统的线性逻辑,不需要进行回压处理;
- 发布者发出数据的速度高于订阅者处理数据的速度,也就是处于"PUSH"状态下。
回压策略(OverflowStrategy)
- IGNORE: 完全忽略下游回压请求
- ERROR: 当下游跟不上上游的速率的时候发出一个错误信号。
- DROP:当下游没有准备好接收新的元素的时候抛弃这个元素。
- LATEST:让下游只得到上游最新的元素。
- BUFFER:缓存下游没有来得及处理的元素(如果缓存不限大小的可能导致OutOfMemoryError)。
声明回压策略
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter, OverflowStrategy backpressure)
操作符调整回压策略
-
onBackpressureBuffer(对于来自其下游的request采取“缓存”策略)
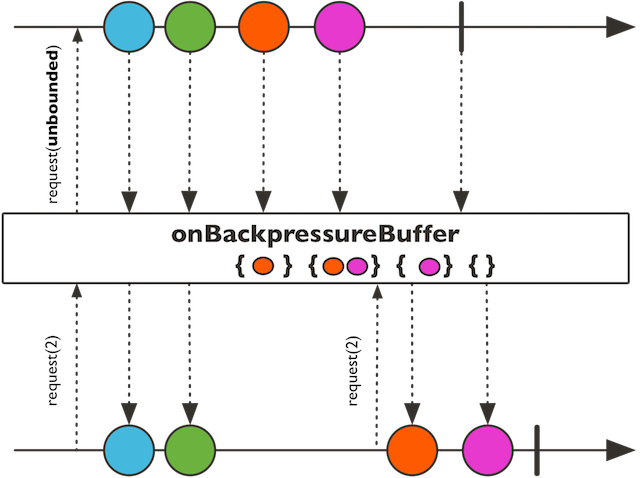
-
onBackpressureDrop(元素就绪时,根据下游是否有未满足的request来判断是否发出当前元素)
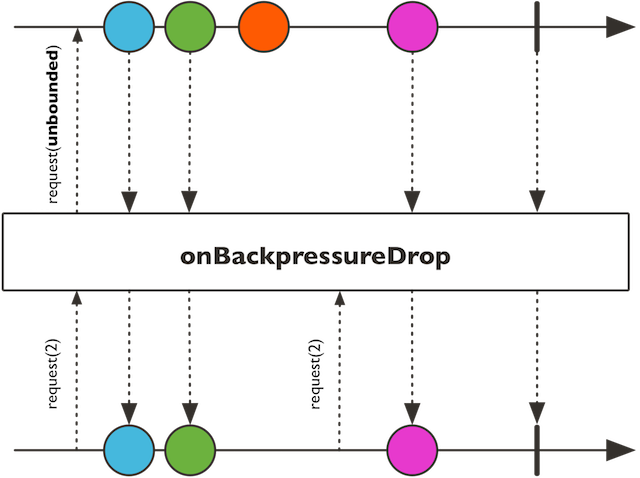
-
onBackpressureLatest(当有新的request到来的时候,将最新的元素发出)
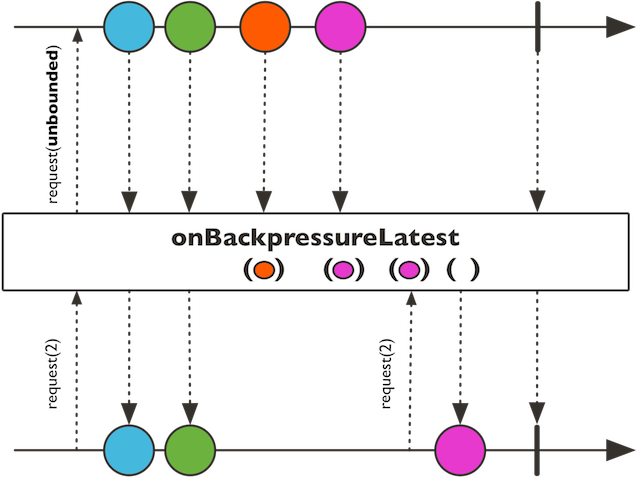
-
onBackpressureError(当有多余元素就绪时,发出错误信号)

通过BaseSubscriber定义自己的Subscriber进行上游流量控制
subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
//hookOnSubscribe定义在订阅的时候执行的操作,订阅时首先向上游请求1个元素
request(1);
}
@Override
protected void hookOnNext(Integer value) {
//hookOnNext定义每次在收到一个元素的时候的操作,每次处理完1个元素后再请求1个。
request(1);
}