读《计算机的心智》,另一个角度看操作系统
多核演变
- 多处理结构(SMP Architecture)
一条总线上挂载多个CPU。CPU角色功能平等,没有主从,称为对称结构。
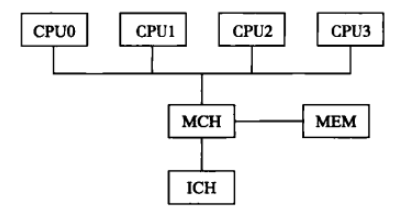
- 超线程结构(HyperThreading)
英特尔提出的技术,让一个CPU同时执行多重线程,从而提高CPU效率。目的是让一个CPU上同时执行多个程序而共享这个CPU内的资源。(让同一时间不同应用程序使用CPU的不同资源,由CPU上的逻辑处理单元指针控制)
如下,4 个物理 CPU ,而每个CPU又因超线程技术分解为两个逻辑 CPU 。每个逻辑 CPU 可以执行一个线程序列。这样一个物理 CPU 可以同时执行两个线程。
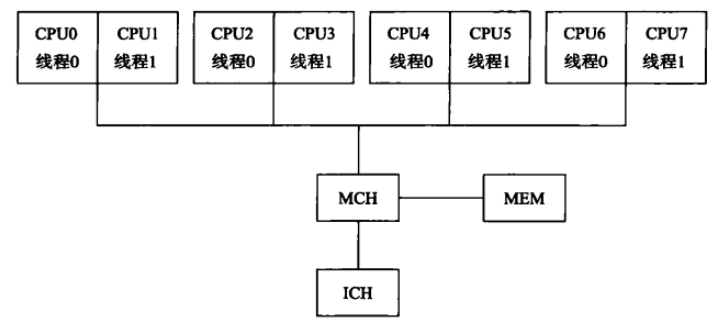
- 多核结构(Multi-core Architecture)
多核结构就是在一个CPU里面布两个执行核,即两套执行单元,如 ALU,FPU和L2缓存等。而其他部分则两个核共享。这样,由于使用的是一个 CPU ,其功耗和单CPU一样。由于布置了多个核,其指令级并行将是真正的并行,而不是超线程结构的半并行。
- 多核超线程结构(Multi-core HyperThreading Architecture)
在多核结构下使用超线程技术。
- 区别 主要体现在同时执行的两个线程之 间共享物理资源的多少。多处理器的共享物理资源最少,每个线程有自己单独的处理器;超线程共享最多,ALU、FPU、MSR、缓存等均为共享物理资源;而多核则介于两者之间,共享处理器,但不共享ALU、FPU等。
多核原理
多核内存结构(协调多核心对内存的访问)
- UMA
将内存作为与执行核独立的单元构建在核之外,所有的核通过同一总线对内存进行访问。由于每个核使用相同的方式访问内存,其到内存的延迟也相同,这种访问模式称为均匀内存访问(Uniform Memory Access , UMA)。
优点是设计简单,实现容易。缺点是难以针对个体的程序进行访问优化,以及扩展困难。随着执行核数最的增加会加剧对共享内存的竞争,造成系统效率急剧下降。
- NUMA
使用多个分开的独立共享内存。每个执行核或 CPU 到达不同共享内存的距离不同,访间延迟也不一样。这种访问延迟不一致的内存共享模式称为非均匀内存访问( Non-Uniform Memo y Access , NUMA)。在这种模式下,最重要的特点是执行核在不同的内存单元面前地位并不平等:到近的内存具有优势地位,到远的内存则处于劣势。
优点是易扩展,但对调度的要求很高(调度时将程序就近执行)。
- COMA
在每个执行核里面配置缓存,其执行需要的数据均缓存在该缓存里面。所有访问由缓存得到满足。避免数据存储的内存单元(远/近),其对效率的影响。这种完全由缓存满足数据访问的模式称为全缓存内存访问( Cache Only Memor Access,COMA)。在这种模式下,每个执行核配备的缓存共同组成全局地址空间。
多处理器之间通信
使用CPU之间中断的机制就是高级可编程中断控制器(APIC)。在此种规范下,每个CPU内部必须内置APIC单元(成为那个CPU的本地APIC)。CPU通过彼此发送中断(IPI,即处理器间中断)来完成它们之间的通信。通过给中断附加动作,不同的CPU可以在某种程度上彼此进行控制。除了每个CPU自己本地的APC外,所有CPU通常还共享一个IO APIC来处理由LO设备引起的中断,这个IO APIC是安装在主板上的。
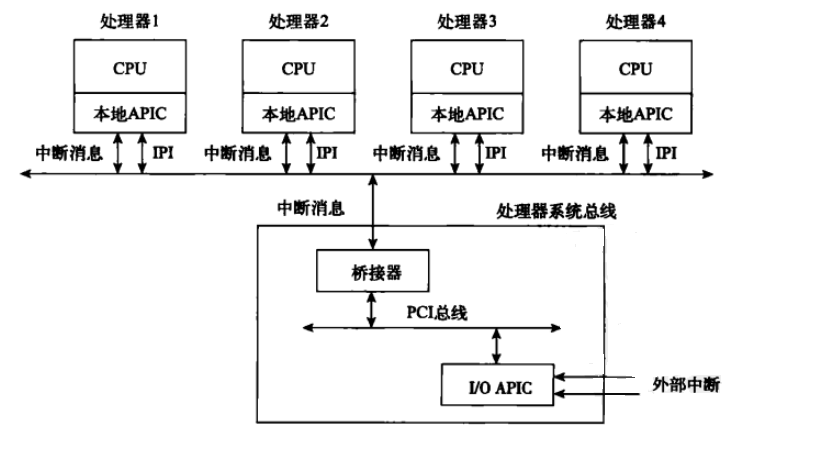
对称多处理器(SMP)的缓存一致性
在对称多处理器结构下,每个处理器都有自己的缓存,因此在一个系统里面存在多个缓存的情况下就有可能出现两个缓存的数据不一致的情况。即两个CPU缓存同样的数据,其中一个或两个CPU对数据进行了修改从而造成两个CPU缓存数据的不同。
MESI模型:CPU中每个缓存行(cacehline)使用4种状态进行标记(使用额外的两位(bit)表示)
- M: 被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
- E: 独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
- S: 共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
- I: 无效的(Invalid)
该缓存是无效的(可能有其它CPU修改了该缓存行)。
- 状态迁移
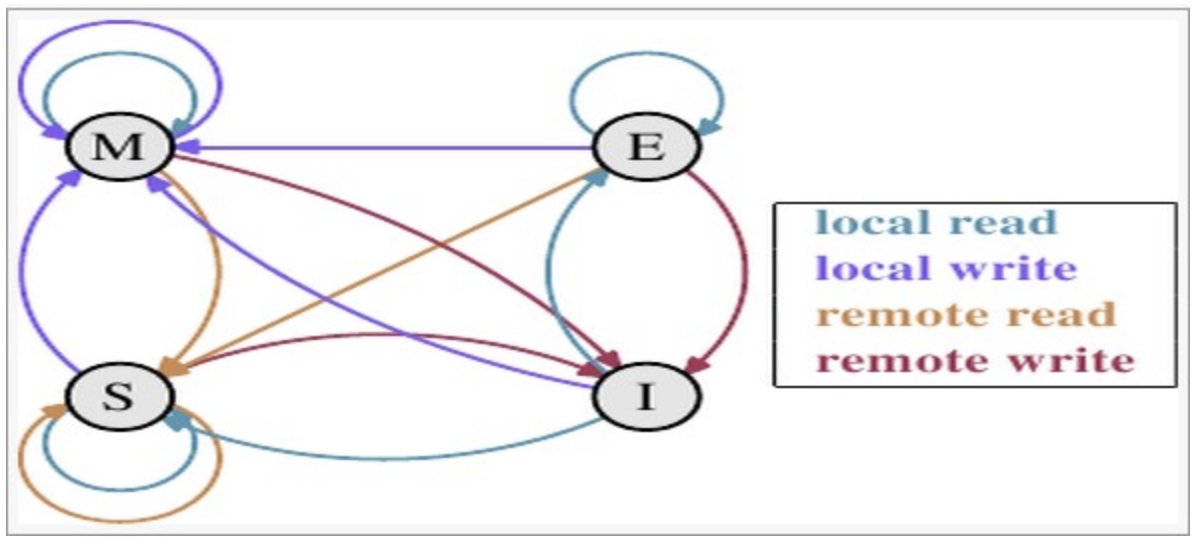
触发事件:
本地读取(Local read) 本地cache读取本地cache数据
本地写入(Local write) 本地cache写入本地cache数据
远端读取(Remote read) 其他cache读取本地cache数据
远端写入(Remote write)其他cache写入本地cache数据
多核环境下的进程同步与调度
同步
- 加载与存入,测试与设置(硬件同步原语)
…
- 总线锁(硬件同步原语)
总线锁就是将总线锁住,只有持有该锁的CPU才能使用总线。这样,由于所有CPU均需要使用共享总线来访问共享内存,而总线的锁住将使得其他CPU没有办法执行任何与共享内存有关的指令,从而使得数据的访问是排他的。
- 软件同步原语
Linux内核提供的原子操作:
总线锁:置换、比较与置换、原子递增操作。
原子算术操作:原子读、设置、加、减、递增、递减、递减与测试。
原子位操作:位设置、位清除;位测试与设置、位测试与清除、位测试与改变。
Windows内核提供的原子:
互锁操作( interlocked operation)
执行体互锁操作( executive interlocked operations
- 旋锁
多核操作系统提供的CPU互斥机制。旋锁通常用于保护某个全局的数据结构,如 Windows里面的DPC(延迟过程调用)队列。这里的互斥指的是多个处理器或执行核之间的互斥,即两个处理器或核不能(物理上)同时访问同一个数据结构。
旋锁通过获取和释放两个操作来保证任何时候只有一个拥有者。旋锁的状态有两种:要么是闲置的,要么被某个CPU所拥有。如果一个CPU获得一个旋锁,那么运行在该CPU上的所有的线程都可以访问该旋锁所保护的寄存器和数据结构。
使用测试与设置实现
旋锁是一个特定的内存单元,位于整个系统的共享内存里面。如果一个处理器要使用旋锁,就必须检査这个特定内存单元的值。如果为0,则将其设置为1,表示获得该旋锁。如果为1,则表示该旋锁被其他处理器所占有,则在该旋锁上进行繁忙等待,即不停地循环。
避免内存总线竞争
每个CPU在检查旋锁的状态时均需要使用系统总线来访间旋锁所在的共享全局内存单元。测试并设置这个全局内存单元,就需要不停地发信号到总线上,造成对内存总线的竞争。
队列旋锁优化:需要旋锁的CPU不要到全局内存去SPIN,而是到自己的局部内存去SPN。这样就可以排除对总线的竞争。需要旋锁的CPU使用队列数据结构(全局内存),旋锁释放的时候就去检查这个队列进行操作。
调度
- 调度策略
每个CPU有着自己的就绪队列( runqueue)。该队列里面又 可以按照不同的优先级分解为多个子队列,就像单核环境下的情况一样。一个进程只可以排在任何一个CPU的队列。
Linux就绪队列:
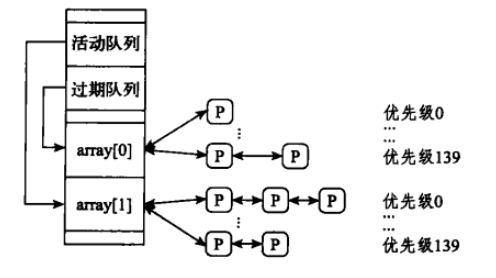
- 调度域(多个CPU负载平衡) 负载平衡的目标是将进程均匀分配到每个CPU的就绪队列里面。Linux CPU负载均衡策略基于多级调度域。
主动负载平衡是队列里面进程数多的CPU将某些进程推出去(push)。被动负载平衡则是队列为空的CPU从别的CPU队列里面将进程拉出来(pu)。