公司数据库账单单表存储过亿,急需优化
优化现有MySql
表设计
- 表字段避免null值出现,null值很难查询优化,占用额外的索引空
- 如果非负则加上UNSIGNED
- 尽量使用TIMESTAMP而非DATETIME
TIMESTAMP:它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。
DATETIME:不做任何改变,基本上是原样输入和输出。
- 索引建立
在WHERE和ORDER BY命令上涉及的列建立索引,利用最左前缀原则:
值分布很稀少的字段不适合建索引
字符字段只建前缀索引
多个单列索引在多条件查询时只会生效第一个索引,所以多条件联合查询时最好建联合索引
离散度大(不同的值多)的列,放在联合索引前面。
...
外层优化
- 通过Redis进行热点缓存
- 通过Elasticsearch进行api对外查询的读写分离
分区[mysql支持的功能,业务代码无需改动]
-
关于分区
- 分区表底层是由多个物理子表组成,对应用是透明的,对分区表的请求会通过句柄对象转化为对存储引擎的接口调用。
- MySql的分区表索引按照分区的子表定义,没有全局索引。
- 查询优化:优化器根据分区函数过滤分区,让查询扫描更少的数据。用户的SQL语句是需要针对分区表做优化,SQL条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区
- 避免分区表存在NULL值(NULL值会使分区过滤无效)
- 对于原生的RANGE分区,LIST分区,HASH分区,分区对象返回的只能是整数值
- explain partitions 查看分区执行计划
-
分区类型
- 范围分区(RANGE)
允许将数据划分不同范围(从属于一个连续区间值的集合)[非null列] PARTITION BY RANGE(YEAR(separated))( PARTITION p0 VALUES LESS THAN(1995), PARTITION p1 VALUES LESS THAN(2000), PARTITION p2 VALUES LESS THAN(2005) );- 列表分区(LIST)允许将数据划分不同范围(从属于一个枚举列表值的集合)[非null列] LIST分区只支持整形,非整形字段需要通过函数转换成整形. PARTITION BY LIST(category)( PARTITION P0 VALUES IN (3,5), PARTITION P1 VALUES IN (1,10), PARTITION P2 VALUES IN (4,9), PARTITION P3 VALUES IN (2), PARTITION P4 VALUES IN (6) );- 哈希分区(HASH)基于给定的分区个数,将数据散列到不同的分区(HASH分区的底层实现基于MOD取余函数) 只能针对整数进行HASH,对于非整形的字段只能通过表达式将其转换成整数 PARTITION BY HASH(id) PARTITIONS 4; -- 分区数- 哈希分区(LINEAR HASH)HASH分区的特殊类型,基于Power-of-Two算法...- KEY分区
基于给定的分区个数,将数据散列到不同的分区(KEY分区的底层实现基于列的MD5算法)
KEY分区对象必须为列,
PARTITION BY KEY(id)
PARTITIONS 2;
-
分区的缺陷
- 分区表,分区键设计不太灵活,如果不走分区键,很容易出现全表锁
- 一旦数据量并发量上来,如果在分区表实施关联,很容易发生灾难
- 对比分库分表:分库分表,自己掌控业务场景与访问模式,可控。分区表,基于mysql底层机制,不太可控
-
分区的优势
- 冷热分离:表非常大且只在表的最后部分有热点数据,冷数据根据分区规则自动归档
- 定期淘汰历史数据:按时间写入,历史数据可淘汰,可快速删除,空间可快速回收
- 优化查询:在where字句中包含分区列时,分区可以大大提高查询效率,减少缓存开销、减少IO开销
- 统计性能提升:在涉及sum()和count()这类聚合函数的查询时,可以在每个分区上面并行处理,最终只需要汇总所有分区得到的结果。
分库分表[业务层改动实施]
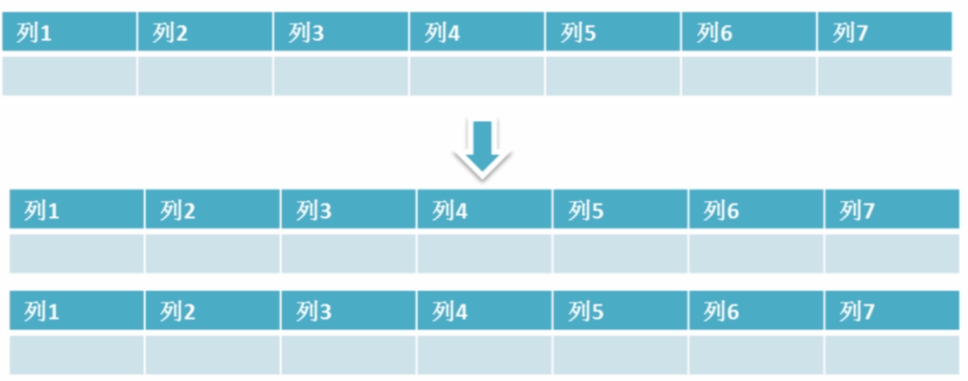
- 垂直拆分表 垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表,建议在数据表设计之初就执行垂直拆分
把不常用的字段单独放在一张表;
把text,blob等大字段拆分出来放在附表中;
经常组合查询的列放在一张表中;
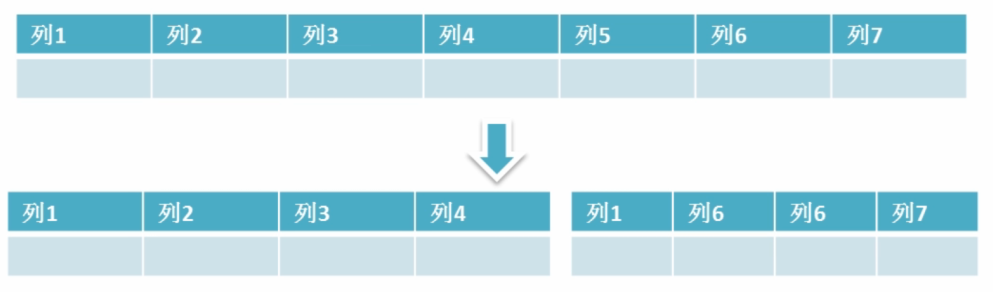
- 水平拆分表 水平拆分是指数据表行的拆分,把一张的表的数据拆成多张表来存放。
通常情况下,我们使用取模的方式来进行表的拆分,在insert时还需要一张临时表uid_temp来提供自增的ID,该表的唯一用处就是提供自增的ID;
- client模式和proxy模式
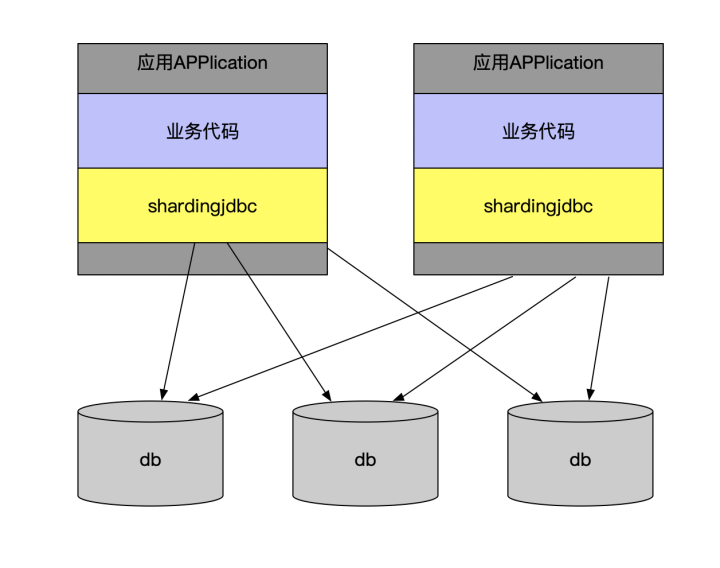
- client模式
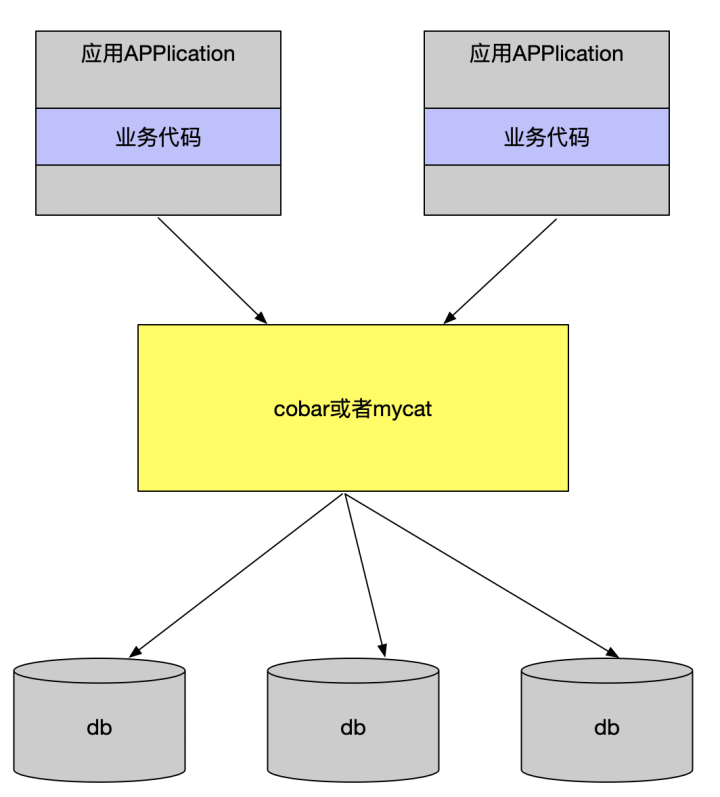
- proxy模式
- client模式
无论是client模式,还是proxy模式,几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。 采用client模式,架构简单,性能损耗也比较小,运维成本低。如果在项目中引入mycat或者cobar,他们的单机模式无法保证可靠性,一旦宕机则服务就变得不可用,你又不得不引入其他中间件(HAProxy)来实现它的高可用集群部署方案
存储升级
升级MySql
- 阿里云POLARDB 关系型分布式云原生数据库,100%兼容MySQL,存储容量最高可达 100T,性能最高提升至 MySQL 的 6 倍。 参考:https://yq.aliyun.com/articles/173291
参考
- <高性能MySql>
- https://zhuanlan.zhihu.com/p/54594681