现代数据栈介绍以及使用DAD(dbt-Airbyte-Dagster)构建现代数据栈实践。
现代数据栈的发展
现代数据栈 (Modern Data Stack,简称MDS) 是由一堆开源工具构成,用于实现数据从摄入到转换到ML,再到后端数据仓库或数据湖,BI仪表盘的端到端分析。该堆栈可以像积木般进行扩展。MDS 的目标是使用最适合每个部分(数据集成、转换、编排、BI…)的工具获得数据洞察。
过去、现在与未来
dbt的创始人Trisan Handy曾对 MDS 发表过一些看法,他将现代数据栈的发展分为三个阶段:
- 寒武纪大爆发 I (2012 - 2016) 以Amazon Redshift的发布为起点,催化了数据栈其他核心产品的增长。Redshift 作为首个云原生的MPP数据库,提供了相较于传统 OLTP 数据库10-1000倍的性能提升,改变了产品构建的方式,提供了更高的可扩展性,更是以低廉的价格打开市场,成为AWS有史以来增长最快的服务。
Redshift 以优异的性能,可扩展性与低廉的价格解决了 数据仓库性能低、请求数限制等问题,意味着围绕解决这些性能问题而构建的 BI 和 ETL 产品都成为了遗留软件,构建适配技术栈的新产品也应运而生,这些产品在很大程度上定义了如今的MDS。
-
部署期 (2016 - 2020) 这段时间内,数据栈产品经历了成熟和部署的过程,功能逐渐稳定,核心功能虽然没有根本性的变化,但可靠性和性能有所提升。
-
寒武纪大爆发 II (2020 - 2025) 进入第三阶段,现代数据栈技术也在逐步变为基于云原生数据平台的技术集合,用于降低运行传统数据平台的复杂性。我们也可以看到现代数据基础架构中遇到的挑战:
- 治理(Governance):数据栈需要更好的治理工具来帮助管理和维护数据资产,增强数据栈的信任度和上下文。
- 实时性(Real-Time):当前数据栈主要基于批处理操作,提供实时或近实时的数据处理有助于扩充场景,降低处理延迟。
- 完成反馈循环(Completing the Feedback Loop):数据不仅用于分析,还可以直接反馈到业务操作中优化决策。
- 数据探索民主化(Democratized Data Exploration):让非技术用户可以更轻松探索与分析数据。
促成现代数据栈广泛采用的技术发展
- 云数据仓库/数据湖的崛起
2000年代,随着数据量的指数级增长,出现了Hadoop、Vertica和MongoDB等技术来处理大量数据,系统通常是分布式SQL或NoSQL。到2010年代初期和中期,云技术开始普及,Redshift、BigQuery和Snowflake等云数据仓库解决方案出现,相对于云数据仓库,本地技术复杂性、成本和所需专业知识较高,使云数据仓库更被广泛采用。
- 速度:云数据仓库显着减少了 SQL 查询的处理时间。
- 连接性:云数据仓库在云中将数据源连接到数据仓库要容易,支持更多的格式和数据源。
- 可扩展性:支持存储资源的动态扩展。
- 成本可控:云数据仓库的定价模型比传统的本地解决方案更加灵活得多,可基于存储的数据量和/或消耗的计算资源。
- 从ETL到ELT的转变
传统 ETL(提取、转换、加载)的方式目的是避免数据仓库过载,云数据仓库的兴起,存储不再是问题,转向ELT(提取、加载、转换)有如下优势:
- 性能和速度:ELT可以利用云数据仓库的计算能力,减少了数据在不同系统之间的移动次数来加速数据处理速度。
- 灵活性:ELT方法支持更实时的数据处理,能够更容易地集成来自不同格式和来源的数据,而无需提前进行复杂的转换。
- 简化成本:ELT方法减少了对源系统和中间系统的依赖,从而减少了硬件和软件成本。
- 简化数据架构:ELT方法简化了数据集成流程,减少了数据移动和重复存储,降低了架构复杂性,也简化了维护工作,易于扩展。
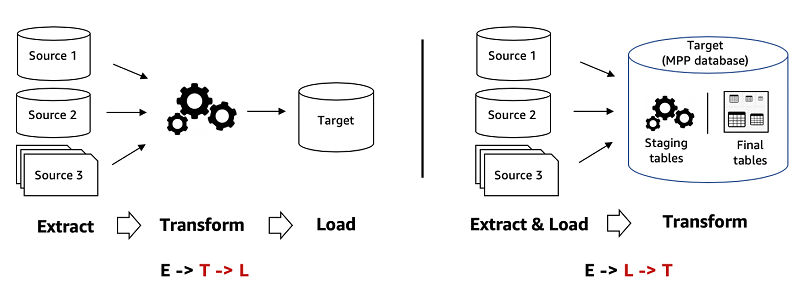
- 自助分析与数据民主化 云数据仓库的兴起不仅促进了从 ETL 到 ELT 的过渡,还促进了BI工具的广泛采用,使更多人能够访问数据并做出数据驱动的决策。
使用现代数据栈来重塑数据工程
现代数据栈的发展趋势对数据工程的影响
- 数据基础设施即服务:随着云服务的兴起,数据库管理员(DBA)的角色正在逐渐消失,而数据基础设施工程师的角色正在向云服务转移。Snowflake、BigQuery、Redshift等提供的按需付费、全托管、弹性服务的托管云数据仓库正在成为主流。
- 数据集成服务:如Airbyte等数据集成平台的兴起减少了数据工程师处理REST API和应用系统孤岛数据集成的工作量。
- 反向ETL:反向ETL是将数据从数据仓库集成到应用系统中的新方法,如通过High Touch 、 Census 和 Airbyte 简化数据同步过程。
- ELT>ETL:采用提取、加载、转换(ELT)更契合现代数据栈,这种方法更合理地利用了分布式云数据库的优化查询引擎。
- 模板化的SQL和YAML:采用模板化的SQL和YAML来管理ELT中的"T”(转换)部分。SQL有着标准化、完善、易于学习和声明性的特点。将此与 Jinja 等模板语言结合起来,可以使其参数化并且更加动态。相比以前的以代码为中心的方法,使用这种纯文本文件方式来表达有着源代码控制,可持续集成和部署的特点,更好进行DataOps实施。
- 计算框架:在转换层出现了更多的抽象,如指标层(Transform.co、MetriQL)、特征工程框架(MLops)、A/B Test框架等。
- 语义层变化:语义层是从技术实现层衍生出来的业务抽象——统一维护业务逻辑、层次结构、计算等的模型层。语义层作为业务抽象层,正在逐步进入转换层(dbt、Airflow)中,通常作为维度建模之上的一层,以创建易于使用的数据结构,通过声明式语义在源代码中控制而不是在特定的 GUI 中进行管理。
- 去中心化治理:数据治理正在从集中式向分散式转变,各个领域专家团队拥有并驱动数据系统,负责数据质量 SLA 并发布指标和维度以供其他部门使用。
现代数据栈组成部分
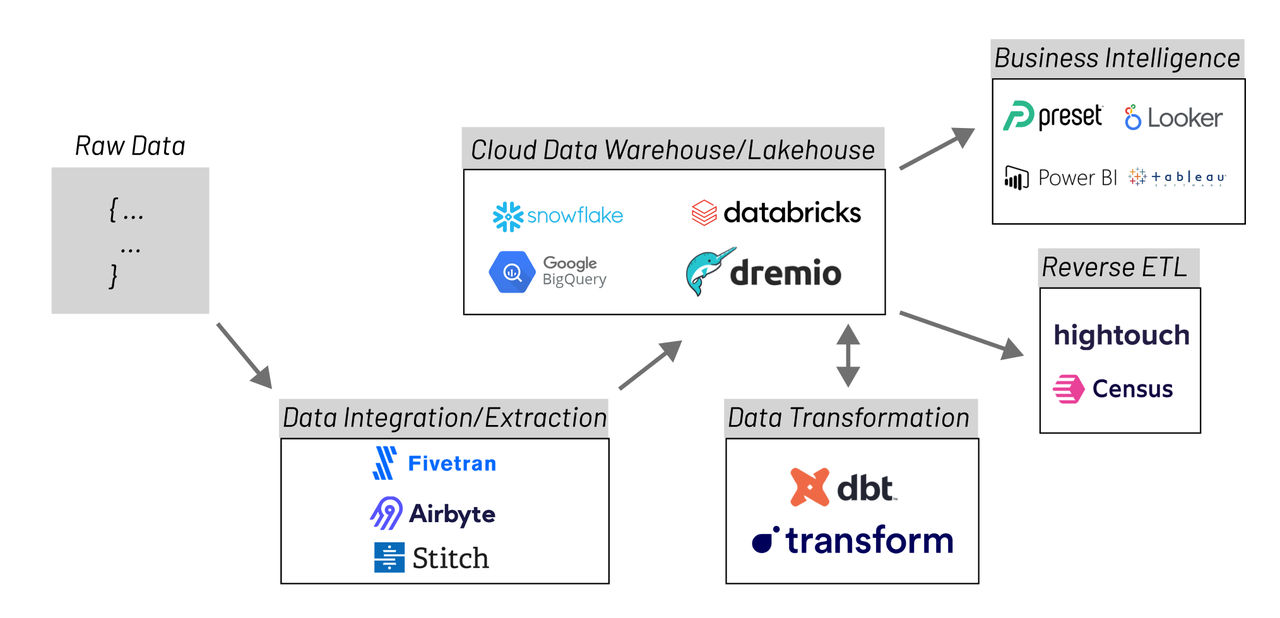
由于现代数据栈工具和技术的数量不断增加,功能变得越加复杂,上图是现代数据栈架构的一个示例图,通常包括以下部分:
- 数据集成(Data Integration):如Airbyte、Fivetran、Stitch等工具,负责从不同系统提取和加载数据到集中式系统中(如数据仓库)。
- 数据转换/建模(Data Transformation/Modeling):如dbt、Transform等工具,用于将原始数据转换为可分析的结构化数据。
- 任务编排(Orchestration):如Airflow、Dagster等工具,用于对数据转换任务进行调度与编排。数据编排可自动执行与数据摄取相关的流程,例如将多个来源的数据汇集在一起、组合并准备进行分析。
- 数据仓库(Data Warehousing):如云数据仓库Snowflake、BigQuery、Redshift等,也有开源数据仓库如Doris、Starrocks、ClickHouse等;数据仓库是现代数据栈的中心,负责存储和管理数据,所有数据都会流入和流出数据仓库。
- 反向ETL(Reverse ETL):如Hightouch、Census等工具,将数据从数据仓库移动到外部系统,反向 ETL 允许您将数据仓库中的数据提供给业务团队。
- 商业智能与分析(BI & Analytics):如Superset、Metabase、Looker等,提供访问和分析数据的工具。
- 数据可观测性(Data Observability):如Amazon CloudWatch、Datadog等,用于监控数据质量和性能。数据可观测性是DevOps中的一个概念,适用于数据、数据管道和平台的环境,使用自动化来监控数据准确性与完整性、数据管道执行状态。
基于dbt、Airbyte、Dagster的开源现代数据栈实践
目标
基于如下开源技术,对现代数据栈的验证实现:
- clickhouse-作为数据仓库
- Airbyte-用于数据集成
- dbt-进行数据转换和质量检测
- Dagster-进行任务编排
- Metabase-作为BI分析工具
完整代码可以在该Github Repo中获得:https://github.com/ChinaLHR/shovel-modern-data-stack。
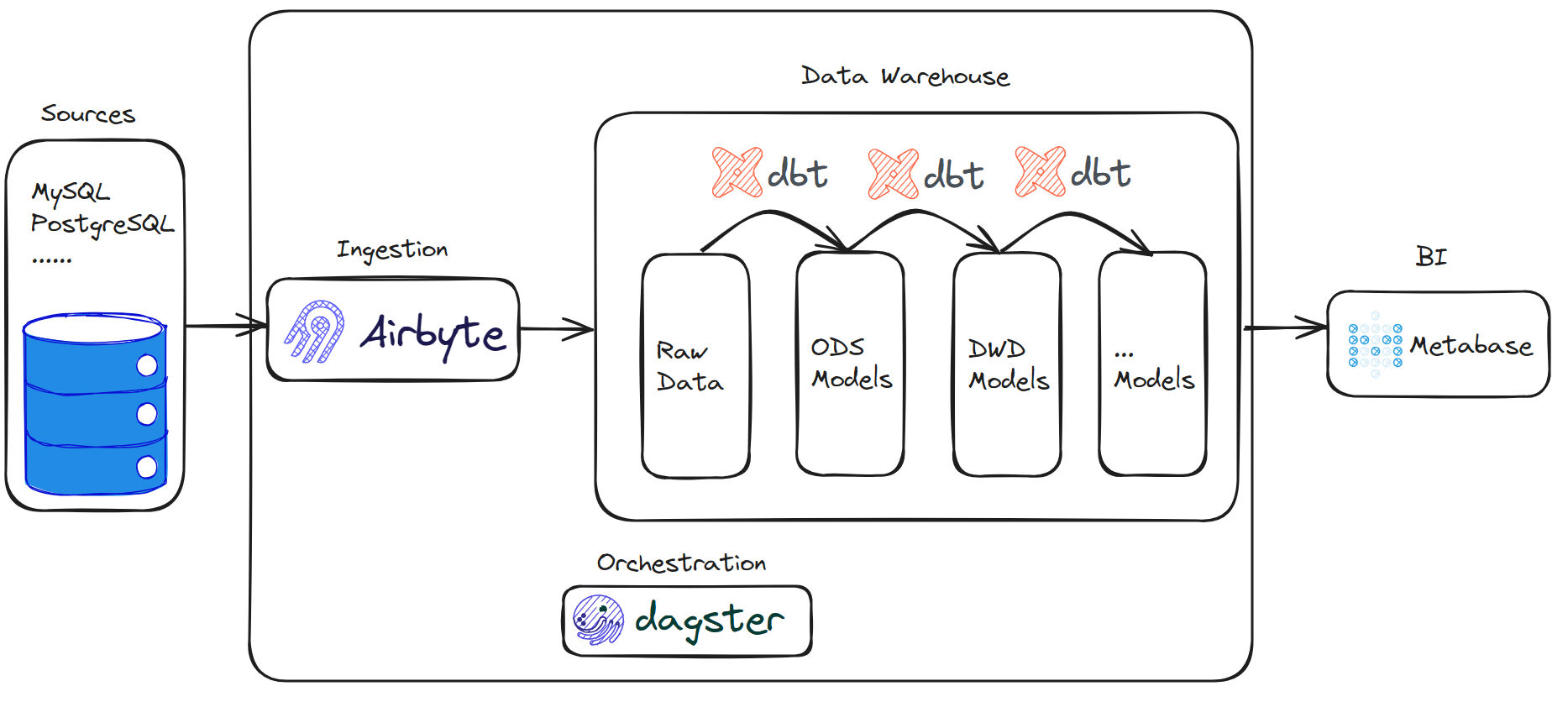
数据流
业务数据库imdb数据集如下所示(该数据源自https://relational-data.org/dataset/IMDb):
通过Airbyte将业务数据库的原始数据加载到数据仓库中,即ODS层数据;随后通过dbt将数据仓库中的ODS层数据进行数据转换为DWD、DWS等明细、汇总层数据;Dagster在这当中充当Airbyte与dbt的协调器,进行同步、转换任务的编排,使我们能够触发和监控该过程。
完整的数据流如下图所示:
数据仓库-ClickHouse
ClickHouse是一个用于联机分析 (OLAP)的列式数据库管理系统 (DBMS),支持标准的SQL语言,由Yandex公司开发,于2016年开源。
ClickHouse采用了列式存储结构,以及使用了数据压缩和代码生成等技术,使其在处理大规模数据时有着极高的性能优势;其基本架构采用典型的分组式分布式架构,通过分片和副本实现高可靠性和可扩展性,很适合用于本地数据仓库,这也是我们选择它的原因。
基于Airbyte进行数据集成
Airbyte 是一款开源数据集成基础设施,用于构建提取和加载(EL)数据管道。Airbyte拥有很高的扩展性和易用性,提供了多达300+连接器,也支持构建自定义连接器。
Airbyte包含三个核心组件:
- connector catalog:包含350多个预建连接器,以及低代码连接器生成器,支持扩展 airbyte 的功能以实现自定义连接器。
- platform:提供配置和扩展数据集成操作所需的服务,支持云管理或自我管理方式。
- user interface: 提供UI、PyAirbyte(Python 库)、API 和 Terraform Provider。
通过Airbyte将MySQL业务数据库的原始数据加载到ClickHouse数据仓库中,需要如下几个步骤:
- 添加MySQL业务数据库到airbyte sources中。
- 添加ClickHouse数据仓库到airbyte destinations中。
- 配置airbyte connections,连通sources 到 destinations,设置同步策略与调度策略,将业务数据库的数据集加载到数据仓库中。

同步完成后表结构如下所示:
name |
----------------------------------------+
data_center_raw__stream_actors |
data_center_raw__stream_directors |
data_center_raw__stream_movies |
data_center_raw__stream_movies_directors|
data_center_raw__stream_movies_genres |
data_center_raw__stream_roles |
create table data_center_raw__stream_actors
(
_airbyte_raw_id String,
_airbyte_data String, -- 原始数据,JSON格式
_airbyte_extracted_at DateTime64(3, 'Asia/Shanghai') default now(),
_airbyte_loaded_at Nullable(DateTime64(3, 'Asia/Shanghai'))
) engine = MergeTree PRIMARY KEY _airbyte_raw_id
ORDER BY _airbyte_raw_id
SETTINGS index_granularity = 8192;
同步模式控制airbyte如何从源读取数据并写入目标,airbyte提供了多种同步模式:
- 增量追加
- 增量追加-删除重复数据
- 全量刷新-覆盖
- 全量刷新-附加
connection如何从source读取数据:
- 增量:读取自上次同步作业后添加到source的记录,一般通过cursor field 或者change data capture (CDC)。
- 全量:每次同步作业都对source的记录进行全量读取。
connection如何向destination写入数据:
- 覆盖:删除destination中的现有数据进行覆盖。
- 追加:将数据追加到destination中。
- 删除重复数据:首先将数据追加到destination中,最终表通过使用主键对中间表进行重复数据删除而生成。
基于dbt进行数据转换
dbt是一个开源工具,使数据从业者能够轻松进行数据转换。使用了Jinja轻量级模板语言,在SQL中使用Jinja提供了一种在查询中使用控制结构的方法,使用dbt可以进行版本控制、模块化、可移植性、CI/CD 和Docs等软件工程最佳实践,更好地实施DataOps。
通过dbt优化工作流程
- 只需要使用SQL Statement或Python DataFrame编写业务逻辑,返回需要的数据集,dbt 负责具体化的实现(创建数据表、进行数据转换)。
- 发布特定数据模型的规范版本,对复杂的业务逻辑进行封装,该模型上的分析动作都将包含相同的业务逻辑,无需重新实现。
- 通过metadata找到long-running模型,dbt的增量模型(incremental models)可以很好地进行优化。
- 利用Jinja模板、macros、Hooks、operations、package management来编写dbt项目;
ref()函数来实现模型的引用,以支持堆叠的模型关系。
dbt中的模型 dbt引入了模型的概念,定义为一个 SQL 语句。模型可以通过多种方式进行物化(materialized,即模型的构建策略)。在dbt中,模型可以交叉引用和分层,以构建更高层次的概念。dbt可以识别模型之间的依赖关系,并确保使用有向无环图(DAG)以适当的顺序创建它们。dbt提供了4种物化类型:
- 临时(ephemeral): 临时模型不构建在数据库中,而是作为公共表表达式被引入到依赖模型中。
- 视图(view): 每次运行时都会重建模型作为视图。
- 物化视图(materialized_view): 允许在目标数据库中创建和维护物化视图。
- 实体表(table): 每次运行时都会将模型重建为表格。
- 增量(incremental): 增量模型允许 dbt 自上次运行该模型以来将记录插入或更新到表中。
安装dbt并连接到ClickHouse
- 安装dbt-core与dbt-clickhouse插件
pip install dbt-core
pip install dbt-clickhouse
- 初始化dbt项目并连接到clickhouse
dbt init data_center
# 初始化后项目结构如下
.
├── analyses
├── dbt_packages
├── macros
├── models
├── README.md
├── seeds
├── snapshots
├── dbt_project.yml
└── tests
# 在model目录下创建imdb文件夹,存放imdb模型
mkdir models/imdb
# 更新dbt_project.yml,指定imdb模型的默认materialized,tags,dagster meta group信息
models:
dbt_data_center:
imdb:
+materialized: view
+tags: "imdb"
+meta:
dagster:
group: "dbt_imdb"
# 更新 ~/.dbt/profiles.yml,添加clickhouse连接信息
clickhouse_data_center:
target: dev
outputs:
dev:
type: clickhouse
schema: data_center
host: your clickhouse host
port: your clickhouse port
user: your clickhouse user
password: 'your clickhouse password'
secure: False
# 在data_center项目目录下执行dbt debug确认环境配置
dbt debug
使用dbt转换airbyte集成的原始数据
通过airbyte从业务数据库加载到数据仓库的原始数据以JSON字符串存储在_airbyte_data字段中,需要使用dbt将其转换为规范化视图,以便后续转换为可供分析的维度模型。
- 在models/imdb/schema.yml文件中定义airbyte加载到数据仓库的表,可在dbt中用于macros,使用
{{ source () }}函数还会在模型和源表之间创建依赖关系。定义关联的dagster asset meta信息,使dagster可以识别到关联的upstream asset。
version: 2
sources:
- name: data_center
tables:
- name: data_center_raw__stream_imdb_actors
meta:
dagster:
asset_key: ["imdb_actors"]
- name: data_center_raw__stream_imdb_directors
meta:
dagster:
asset_key: ["imdb_directors"]
- name: data_center_raw__stream_imdb_directors_genres
meta:
dagster:
asset_key: ["imdb_directors_genres"]
- name: data_center_raw__stream_imdb_movies
meta:
dagster:
asset_key: ["imdb_movies"]
- name: data_center_raw__stream_imdb_movies_directors
meta:
dagster:
asset_key: ["imdb_movies_directors"]
- name: data_center_raw__stream_imdb_movies_genres
meta:
dagster:
asset_key: ["imdb_movies_genres"]
- name: data_center_raw__stream_imdb_roles
meta:
dagster:
asset_key: ["imdb_roles"]
- 创建models/imdb/ods_imdb_actors.sql … 模型,使用materialized view将原始表转换为ods层模型。模型会在每次运行时通过ClickHouse中的
CREATE VIEW AS语句重新构建为view。
{{ config(materialized='view') }}
WITH source AS (
SELECT * FROM {{ source('data_center', 'data_center_raw__stream_imdb_actors')}}
),
ods_imdb_actors as (
SELECT
toUInt32(JSONExtractString(_airbyte_data, 'id')) AS id,
toUInt32(JSONExtractString(_airbyte_data, 'film_count')) AS film_count,
JSONExtractString(_airbyte_data, 'first_name') AS first_name,
JSONExtractString(_airbyte_data, 'last_name') AS last_name,
JSONExtractString(_airbyte_data, 'gender') AS gender,
parseDateTimeBestEffort(JSONExtractString(_airbyte_data, '_ab_cdc_updated_at')) AS updated_at
FROM
source
)
select *
from ods_imdb_actors
使用dbt将ods层数据转换为dwd维度模型
创建dwd_imdb_actors_movies.sql模型,将actors、movies、directors等ods层view转换为dwd层的演员参演电影明细表dwd_imdb_actors_movies。这里使用dbt提供的incremental materializations方式,支持增量执行,将自上次执行以来的记录插入或更新到表中,避免每次都重复构造实体表。在模型中使用incremental materializations方式,需要提供添加:
- unique_key: 确保实体化表中没有重复的行。
- incremental filter: dbt通过该过滤方式来识别增量运行中哪些行发生了更改。
{{ config(engine='MergeTree()', materialized='incremental', unique_key='id') }}
with dwd_imdb_actors_movies as (
SELECT {{ref('ods_imdb_actors')}}.id as id,
concat({{ref('ods_imdb_actors')}}.first_name, ' ', {{ref('ods_imdb_actors')}}.last_name) as actor_name,
{{ref('ods_imdb_movies')}}.id as movie_id,
{{ref('ods_imdb_movies')}}.name as movie_name,
{{ref('ods_imdb_movies')}}.rank as movie_rank,
{{ref('ods_imdb_movies_genres')}}.genre as movie_genre,
concat({{ref('ods_imdb_directors')}}.first_name, ' ', {{ref('ods_imdb_directors')}}.last_name) as director_name,
{{ref('ods_imdb_actors')}}.updated_at as updated_at
FROM {{ref('ods_imdb_actors')}}
LEFT JOIN {{ref('ods_imdb_roles')}} ON {{ref('ods_imdb_roles')}}.actor_id = {{ref('ods_imdb_actors')}}.id
LEFT JOIN {{ref('ods_imdb_movies')}} ON {{ref('ods_imdb_movies')}}.id = {{ref('ods_imdb_roles')}}.movie_id
LEFT JOIN {{ref('ods_imdb_movies_genres')}} ON {{ref('ods_imdb_movies_genres')}}.movie_id = {{ref('ods_imdb_movies')}}.id
LEFT JOIN {{ref('ods_imdb_movies_directors')}} ON {{ref('ods_imdb_movies_directors')}}.movie_id = {{ref('ods_imdb_movies')}}.id
LEFT JOIN {{ref('ods_imdb_directors')}} ON {{ref('ods_imdb_directors')}}.id = {{ref('ods_imdb_movies_directors')}}.director_id
)
select * from dwd_imdb_actors_movies
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
使用dbt将dwd维度模型转换为dws维度模型
创建dws_imdb_actors_movies.sql模型,在dwd_imdb_actors_movies维度模型上进行分析,得出演员的摘要信息表。
{{ config(materialized='view') }}
with dws_imdb_actors_movies as (
SELECT {{ref('dwd_imdb_actors_movies')}}.id,
any({{ref('dwd_imdb_actors_movies')}}.actor_name) as name,
uniqExact({{ref('dwd_imdb_actors_movies')}}.movie_name) as num_movies,
avg({{ref('dwd_imdb_actors_movies')}}.movie_rank) as avg_rank,
uniqExact({{ref('dwd_imdb_actors_movies')}}.movie_genre) as unique_genres,
uniqExact({{ref('dwd_imdb_actors_movies')}}.director_name) as uniq_directors
FROM
{{ref('dwd_imdb_actors_movies')}}
GROUP BY {{ref('dwd_imdb_actors_movies')}}.id
)
select *
from dws_imdb_actors_movies
运行dbt进行数据转换
- 在data_center项目下执行
dbt run进行数据转换。 dbt会根据models目录下定义的模型在 目标数据仓库中进行数据转换,创建对应的view、table。
❯ dbt run
03:39:49 Running with dbt=1.8.2
03:39:49 Registered adapter: clickhouse=1.8.0
03:39:49 [WARNING]: Configuration paths exist in your dbt_project.yml file which do not apply to any resources.
There are 1 unused configuration paths:
- models.data_center.imdb
03:39:50 Found 8 models, 7 sources, 441 macros
03:39:50
03:39:50 Concurrency: 1 threads (target='dev')
03:39:50
03:39:50 1 of 8 START sql view model `data_center`.`ods_imdb_actors` .................... [RUN]
03:39:50 1 of 8 OK created sql view model `data_center`.`ods_imdb_actors` ............... [OK in 0.13s]
03:39:50 2 of 8 START sql view model `data_center`.`ods_imdb_directors` ................. [RUN]
03:39:50 2 of 8 OK created sql view model `data_center`.`ods_imdb_directors` ............ [OK in 0.06s]
03:39:50 3 of 8 START sql view model `data_center`.`ods_imdb_movies` .................... [RUN]
03:39:50 3 of 8 OK created sql view model `data_center`.`ods_imdb_movies` ............... [OK in 0.06s]
03:39:50 4 of 8 START sql view model `data_center`.`ods_imdb_movies_directors` .......... [RUN]
03:39:50 4 of 8 OK created sql view model `data_center`.`ods_imdb_movies_directors` ..... [OK in 0.06s]
03:39:50 5 of 8 START sql view model `data_center`.`ods_imdb_movies_genres` ............. [RUN]
03:39:50 5 of 8 OK created sql view model `data_center`.`ods_imdb_movies_genres` ........ [OK in 0.06s]
03:39:50 6 of 8 START sql view model `data_center`.`ods_imdb_roles` ..................... [RUN]
03:39:50 6 of 8 OK created sql view model `data_center`.`ods_imdb_roles` ................ [OK in 0.06s]
03:39:50 7 of 8 START sql incremental model `data_center`.`dwd_imdb_actors_movies` ...... [RUN]
03:39:51 7 of 8 OK created sql incremental model `data_center`.`dwd_imdb_actors_movies` . [OK in 0.26s]
03:39:51 8 of 8 START sql view model `data_center`.`dws_imdb_actors_movies` ............. [RUN]
03:39:51 8 of 8 OK created sql view model `data_center`.`dws_imdb_actors_movies` ........ [OK in 0.07s]
03:39:51
03:39:51 Finished running 7 view models, 1 incremental model in 0 hours 0 minutes and 0.99 seconds (0.99s).
03:39:51
03:39:51 Completed successfully
03:39:51
03:39:51 Done. PASS=8 WARN=0 ERROR=0 SKIP=0 TOTAL=8
- 通过
dbt docs generate命令生成模型文档信息 - 通过
dbt docs serve运行dbt docs服务,可以看到models的Lineage Graph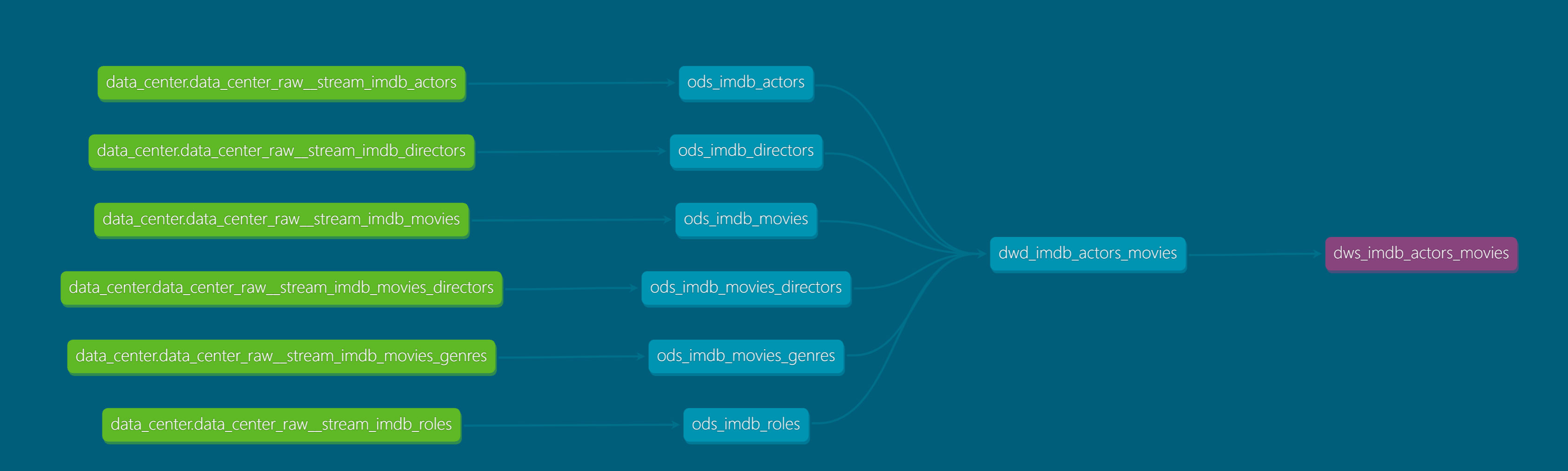
基于Dagster进行任务编排
Dagster是一个开源数据编排器,专门用于开发和维护数据资产(例如表、数据集、机器学习模型和报表),可以让我们以正确的顺序自动运行数据管道中的数据集成、数据转换步骤,确保数据资产的准确性。
Dagster可以很好地整合airbyte与dbt,对数据集成与数据转换任务进行编排、观测、诊断。
核心概念
-
Asset (资产) 资产是Dagster的核心概念,可以是数据库表或者视图、对象存储中的文件、机器学习模型、数据集成或者数据转换管道等持久性存储中的对象。通过
@asset装饰器创建Asset Definitions,并维护它们间的依赖关系。 -
Jobs (任务) Jobs是Dagster中执行和监控Asset Definitions的主要单元,以一系列Assert为目标,可以在Dagster UI手动触发、调度任务触发、GraphQL API触发。
-
Automation(自动化) Dagster 提供了多种自动化运行数据管道的方法,如调度任务(schedules)、事件触发器(event-based triggers)。
-
Resources(资源) 在数据工程中,Resources是用于完成工作的外部服务、工具和存储。如ETL管道中使用的获取数据的API、数据仓库、BI工具…。可以在Defintions定义中关联Resources,作为Asset的参数来指定Resources与Asset的依赖关系。
-
Ops(计算) Ops是Dagster中的核心计算单元,单个Ops应执行相对简单的任务(数据集成、数据查询、数据转换、数据存储…), 支持对多个Ops进行数据编排执行。
-
Code locations (代码定位) Definitions包含代码定位中定义的所有对象,包括asset、job、resource、schedule和sensors。
defs = Definitions(
assets=[dbt_customers_asset, dbt_orders_asset],
schedules=[bi_weekly_schedule],
sensors=[new_data_sensor],
resources=[dbt_resource],
)
安装Dagster并初始化项目
pip install dagster dagster-airbyte dagster-dbt dagster-webserver
# 使用dagster-dbt创建模板项目,指定dbt项目目录
dagster-dbt project scaffold --project-name orchestration_data_center --dbt-project-dir ./dbt_data_center --use-experimental-dbt-project
# 初始化后项目结构如下
├── orchestration_data_center
│ ├── assets.py
│ ├── definitions.py
│ ├── project.py
│ └── schedules.py
├── pyproject.toml
└── setup.py
Dagster集成Airbyte、dbt
初始化完项目后,在assets.py文件中,我们需要集成Airbyte与dbt,将Airbyte的connection与dbt的model加载为Dagster的asset。
import os
from dagster import AssetExecutionContext, EnvVar
from dagster_dbt import DbtCliResource, dbt_assets
from dagster_airbyte import AirbyteResource, load_assets_from_airbyte_instance
from .project import dbt_data_center_project
airbyte_instance = AirbyteResource(
host="your airbyte host",
port="8000",
# If using basic auth, include username and password:
# username="airbyte",
# password=os.getenv("AIRBYTE_PASSWORD")
)
imdb_airbyte_assets = load_assets_from_airbyte_instance(
airbyte_instance,
connection_filter=lambda meta: "imdb_to_data_center" in meta.name,)
@dbt_assets(manifest=dbt_data_center_project.manifest_path,select='tag:dbt_imdb')
def imdb_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
数据编排
Dagster中实现数据编排,即是对asset依赖关系的确定,dbt项目中对airbyte集成的原始数据依赖,可以通过上文描述的,在dbt schema.yml文件中,通过meta-dagster-asset_key定义source的upstream asset。而dbt中各模型间的依赖关系,Dagster会自动从dbt项目的Lineage Graph中获取。
定义ELT pipeline 相关的Job、Schedule、Definitions
在schedules.py文件中,定义job与schedules,描述任务执行的关联asset与调度方式。
from dagster import define_asset_job, ScheduleDefinition, Definitions
run_all_asset_job = define_asset_job("run_all_asset", selection="*")
schedules_every_half_hour = [
ScheduleDefinition(
job=run_all_asset_job,
cron_schedule="*/30 * * * *",
)
]
在definitions.py文件中,定义Definitions,描述ETL pipeline关联的asset、schedules、resources。
from dagster import Definitions
from dagster_dbt import DbtCliResource
from .assets import imdb_dbt_assets,imdb_airbyte_assets
from .project import dbt_data_center_project
from .schedules import schedules_every_half_hour
imdb_etl_defs = Definitions(
assets=[imdb_airbyte_assets,imdb_dbt_assets],
schedules=schedules_every_half_hour,
resources={
"dbt": DbtCliResource(project_dir=dbt_data_center_project),
},
)
运行dagster webserver
dagster-webserver -h 0.0.0.0 -p 3000
在Dagster UI上Deployment上可以看到我们定义Definitionsorchestration_data_center,关联的ETL pipeline 调度任务会每30分执行一次,根据既定的依赖关系,先调用Airbyte进行数据集成,然后使用dbt进行数据转换,最终完成维度模型的创建与更新。
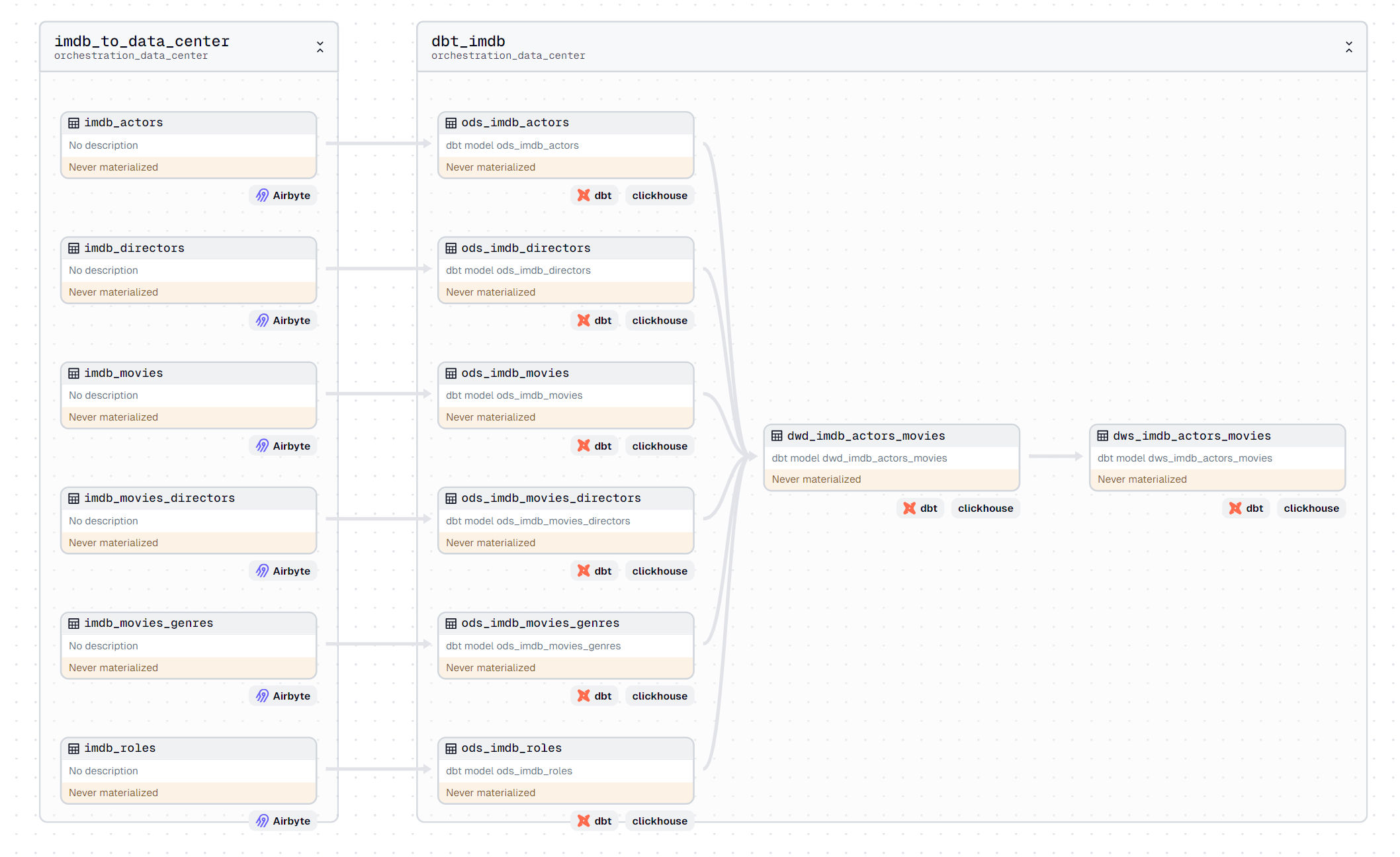
基于Metabase实现BI分析
使用Metabase连接到我们的数据仓库,在使用Airbyte,dbt,Dagster完成数据集成,数据转换,数据编排与自动化pipeline执行操作后,就可以轻松地在Metabase中使用转换好的维度模型进行BI分析与展示。
总结
基于dbt、Airbyte、Dagster的现代数据栈使得我们可以很方便地进行数据集成、数据转换、任务编排;模板化的模型构建可以更好地进行代码控制,持续集成和部署,更好进行DataOps实施。